


今天,又一家公司要吊打英伟达。
据一家名为Tachyum公司透露,公司新发布的 2nm Prodigy 芯片能提供 1024 个核心、6GHz 时钟频率、1GB 组合缓存,并支持超高速 DDR5 内存,理论上可以轻松应对 NVIDIA 的 Rubin Ultra,
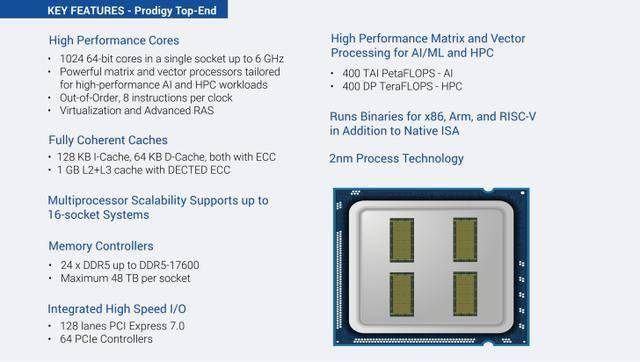
Tachyum表示, 公司的 Prodigy 2nm 处理器将在单个插槽上实现多达 1024 个 64 位核心,从而将性能提升到一个新的水平。这些核心的运行频率最高可达 6.0 GHz,并且可以扩展到 16 插槽系统,最多可容纳 8192 个 CPU 核心(1024 核心 SKU 支持 8 插槽配置)。
Tachyum 声称, Prodigy 2 将是首款推理性能超过 1000 PFLOPs 的芯片,而 NVIDIA Rubin 的推理性能为 50 PFLOPs。换而言之,该公司的芯片速度比 NVIDIA Rubin Ultra 快 21 倍。
他们还指出,Prodigy Ultimate 的 AI 机架性能比 NVIDIA Rubin Ultra (NVL756) 高 21.3 倍,而 Prodigy Premium 的 AI 机架性能比 NVIDIA Rubin (NVL144) 高 25.9 倍。但他们并未详细说明 Prodigy Premium 和 Prodigy Ultimate 的具体区别。
下面我们了解一下这颗预告了多次,并延期了多次的芯片。
解码Tachyum的芯片
虽然他们并没有详细讲述这颗芯片,但我们可以从相关报道中,获得更多蛛丝马迹。
Tachyum也强调,过去几年,公司不断升级其 Prodigy 设计,以满足服务器、人工智能和高性能计算市场不断变化的需求,其整数性能提升高达 5 倍,人工智能性能提升高达 16 倍,DRAM 带宽提升 8 倍,芯片间和 I/O 带宽提升 4 倍,通过支持 16 个插槽实现 4 倍的可扩展性,以及 2 倍的能效,同时降低了每个核心的成本。
现在,随着Prodigy芯片升级至2nm工艺,显著降低了功耗。尽管2nm晶圆成本高昂,但缩小芯片尺寸仍能降低成本。Prodigy封装中的每个芯片都集成了256个高性能定制64位内核。由于多个芯片共用一个封装,因此降低功耗至关重要。在近期2.2亿美元投资的支持下,2nm Prodigy芯片正准备进行流片。
接下来,我们看一下这颗芯片的规格:规格概览:2nm架构(尚未制造)、最多可达 1024 个 64 位核心、最高可达 6 GHz 时钟频率、最多 1 GB 的 LLC、最高可达 1600W TDP、支持高达 DDR5-17,600 MT/s 的速度、每个插槽最高支持 48 TB DDR5 内存容量、最多支持 128 条 PCIe 7.0 通道。
Tachyum介绍说,其用于Prodigy 2nm芯片的64位微架构将支持最新的矩阵和向量扩展,专为高性能人工智能和高性能计算应用而设计。它采用乱序执行架构,每个时钟周期可执行8条指令。
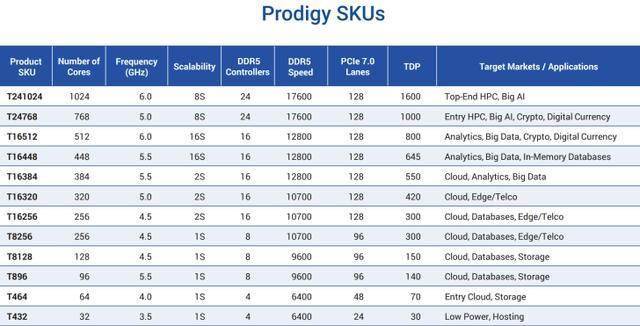
他们指出,该芯片本身集成了 128 KB 指令缓存 (I-Cache)、64 KB 数据缓存 (D-Cache)(均支持 ECC)以及 1 GB 的 L2+L3 缓存。SKU 提供 32、64、96、128、256、320、384、448、512、768 和 1024 个核心配置,TDP 则从 30W、70W、140W、150W、300W、420W、550W、645W、800W、1000W 到最高 1600W 不等。
Prodigy 2nm芯片将支持多达24个DDR5通道,速度最高可达17,600 MT/s,每个插槽最大容量可达48 TB。I/O方面,将提供128条PCIe 7.0通道和总共64个PCIe控制器。DDR5-17600规格和PCIe 7.0在现有服务器市场并不常见,因此Tachyum今天提到的这个平台不太可能在2027年之前上市,即使到2030年,如果他们能够推出类似的产品,那也堪称奇迹。
在此前的报道中,Tachyum 曾透露,公司的Prodigy 处理器将采用多芯片设计,系统级封装 (SiP) 内的每个计算芯片都将拥有 256 个通用核心。这意味着整个 SiP 将提供更多核心,从而兑现该公司“性能是目前最高性能 x86 处理器的 3 倍,是目前最高性能 HPC 通用图形处理器 (GPGPU) 的 6 倍”的承诺。然而,这一性能承诺存在一个问题:该公司尚未最终确定 CPU 的规格,因此也尚未完成芯片流片,其实际性能仍有待观察。
规格参数介绍完毕,我们来看看Tachyum公布的一些性能数据。首先,Tachyum将其Prodigy 2nm芯片与NVIDIA的Rubin Ultra GPU平台进行了比较,后者预计将于2027年发布。
Tachyum强调,Prodigy 通用处理器可提供数量级更高的 AI 性能,是最佳 x86 处理器的 3 倍,是速度最快的 GPGPU 的 6 倍 HPC 性能。Prodigy 无需昂贵的专用 AI 硬件,并可显著提高服务器利用率,从而大幅降低数据中心的资本支出和运营支出,同时提供前所未有的性能、功耗和经济效益。
Tachyum表示,除了开源所有软件外,Tachyum 还开放其内存技术,采用标准组件,使基于 DIMM 的内存带宽提升 10 倍,并可供内存或处理器公司授权使用,包括采用 JEDEC 标准,以实现高普及率和低成本。2023 年,Tachyum 发布了可授权的 Tachyum AI (TAI) 数据类型,其 Tachyum 处理单元 (TPU) 内核也已开放授权。Tachyum 目前正在推进指令集架构 (ISA) 的开源。
基于这些领先芯片,Tachyum打造了两个解决方案,其中Prodigy Ultimate 集成了 1024 个高性能内核、24 个 DDR5 17.6GT/s 内存控制器和 128 条 PCIe 7.0 通道;Prodigy Premium 配备 16 个 DRAM 通道,内核数量从 512 个到 128 个不等,可扩展至 16 路系统。入门级 Prodigy 配备 8 个或 4 个 DRAM 控制器,内核数量从 128 个到 32 个不等。
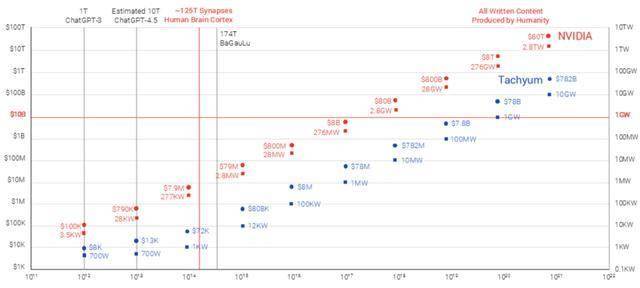
如Tachyum所说,传统的大规模人工智能解决方案可能耗资超过 8 万亿美元,需要超过 276 GW的电力。相比之下,Tachyum 的解决方案预计仅需 780 亿美元的成本和 1 GW的电力即可实现类似的功能,使其能够被多家公司和国家所采用。Tachyum认为,公司的Prodigy 系列产品能股改多种性能和应用领域,包括大型人工智能、百亿亿次级超级计算、高性能计算 (HPC)、数字货币、云计算/超大规模计算、大数据分析和数据库。
Tachyum强调,Prodigy 的卓越功能、可扩展性和价格定位确保了其快速的市场渗透。Tachyum 提供开箱即用的原生系统软件、操作系统、编译器、库、众多应用程序和 AI 基础设施框架。它还允许运行未经修改的 Intel/AMD x86 二进制文件,并将其与原生应用程序混合使用。这确保了客户从第一天起就能使用 Tachyum 系统。
一家旨在打造通用芯片的公司
Tachyum公司总部位于加利福尼亚州圣克拉拉,并在斯洛伐克首都布拉迪斯拉发设有研发实验室,其团队拥有众多经验丰富的工程师和高管。
其中,联合创始人兼首席执行官Radoslav Danilak早在互联网泡沫初期就设计了自己的超长指令字(VLIW)处理器,几年后,他为一家名为Gizmo Technology的公司开发了一款64位处理和内存的乱序执行x86处理器,之后他曾在东芝公司担任首席架构师,负责东芝7901芯片的开发。该芯片是MIPS R5900 Emotion Engine处理器的变体,曾用于PlayStation 2游戏机,据推测也用于东芝的各种微控制器和电子产品中。
Danilak还曾在Nishan Systems公司参与一个为期一年的项目,开发出一款单芯片网络处理单元(NPU),将20个不同芯片的功能整合到一起。之后,他担任英伟达的高级架构师,负责设计nForce 4 GPU和第一代Tesla GPU加速器“Fermi”的特性。
2007年,正值GPU加速浪潮即将兴起之际,Danilak离开了英伟达。他创立了闪存存储制造商SandForce,并为其开发了自主研发的闪存控制器。2010年,SandForce以3.77亿美元的价格出售给了LSI Logic。此后,Danilak联合创立了全闪存阵列制造商Skyera,该公司于2015年夏季被西部数据以未公开的价格收购。
之后,他四处寻找新的创业灵感,并在2016年9月与Mullendore和Igor Shevlyakov共同创立了Tachyum公司。
Mullendore在互联网泡沫时期及之后曾担任Nishan Systems的高级架构工程师,之后在存储区域网络交换机制造商McData工作,该公司最初隶属于EMC,后被Brocade Communications收购,Mullendore在收购后继续留任了一段时间。随后,Mullendore加入SandForce担任首席架构工程师,之后又跟随Danilak先后加入Skyera,现在则在Tachyum工作。
Tachyum 的另一位联合创始人 Shevlyakov 于 20 世纪 90 年代初以软件工程师的身份入行,随后在互联网泡沫初期,他曾在俄罗斯多家初创公司专注于编译器开发。在 1999 年至 2001 年的巅峰时期,他担任实时操作系统制造商 Wind River 的高级编译器工程师。之后,Shevlyakov 在 MicroUnity 工作了十余年,该公司开发了一款名为 BroadMX 的 RISC/SIMD 处理器,旨在用于网络处理任务。在 MicroUnity,他将 GNU 开源工具链移植到了该处理器上。随后,他与 Danilak 和 Mullendore 一起加入了 Skyera 公司,在那里,他将 GNU 工具链移植到了该公司自主研发的用于控制闪存的芯片上,并参与了全闪存阵列中闪存转换层的开发工作。西部数据收购 Skyera 后,Shevlyakov 继续留在 Tachyum,与他的联合创始人一起工作,并负责 Tachyum 的软件栈开发。
负责业务拓展的副总裁肯·瓦格纳(Ken Wagner)也是联合创始人之一,曾就职于多家硅芯片初创公司。系统工程副总裁基兰·马尔万卡(Kiran Malwankar)是横向扩展存储设备制造商Pavilion Data Systems的创始人。弗雷德·韦伯(Fred Weber)是超级计算机制造商Encore Computer和Kendall Square的联合创始人,曾任AMD首席技术官,并参与创建了64位Athlon和Opteron架构,他是公司的顾问。曼彻斯特大学计算机科学教授史蒂夫·弗伯(Steve Furber)也是顾问,他在20世纪80年代设计了首款32位Acorn RISC Machines处理器,也就是我们熟知的Arm。分布式系统专家克里斯托斯·科兹拉基斯(Christos Kozyrakis)是斯坦福大学的教授,他经常与谷歌合作,也是公司的顾问。
在过去近十年里,Prodigy芯片的设计已延期多年。
一开始,该公司拥有一个内部System C模拟器,可用于内部开发和基准测试。早在2020年的时候,该公司就说芯片将流片,将采用台积电的7纳米工艺制造。这种先进的制造工艺使其能够在290平方毫米的器件中集成大量组件。
如图所示,该设计源于对连接电路模块的导线的深入研究,以及Tachyum认为能够吸引超大规模数据中心、高性能计算中心以及机器学习和推理集群的组件比例的合理配置。Danilak指出,问题在于导线的传输速度正在变慢。以下是一些常见的图表:
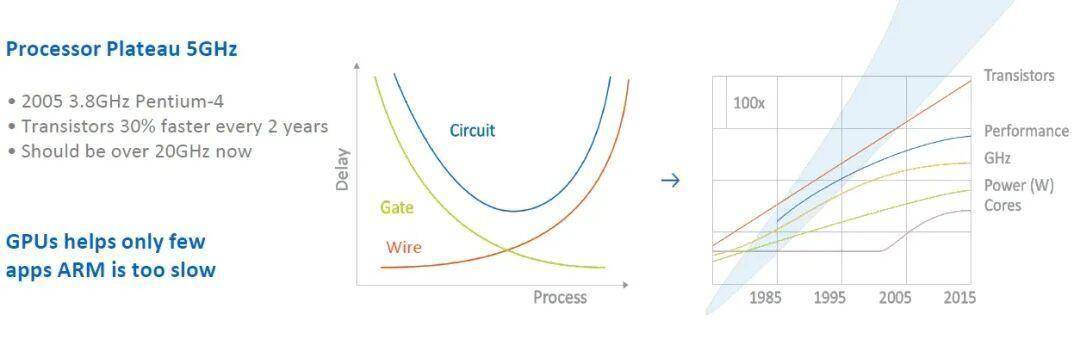
“我们在时钟频率附近遇到了性能瓶颈,每个核心的性能增长并不显著,”Danilak表示。“核心数量在增加,但由于散热问题,我们也在降低时钟频率。所有晶体管的速度都在提高,但问题在于导线变得越来越细,电阻越来越大,因此导线延迟也在增加。过去芯片的延迟是每毫米100皮秒,而现在每毫米的延迟已经接近1000皮秒。”
当然,导线电阻会产生热量,还会导致延迟,因此,Danilak认为,诀窍在于尽可能缩短导线长度。这样一来,芯片的时钟频率可以比以往更高,同时还能减少总计算时间(获取数据的时间加上处理数据的时间),从而完成更多工作。关键在于提取芯片上运行的工作负载中的并行性,从而消除导线造成的计算延迟(就像缓存层次结构掩盖了标准处理器中的计算延迟一样),而这需要一些巧妙的编译器工作——这时,Shevlyakov拥有如此丰富的编译器经验就能发挥重要的作用。
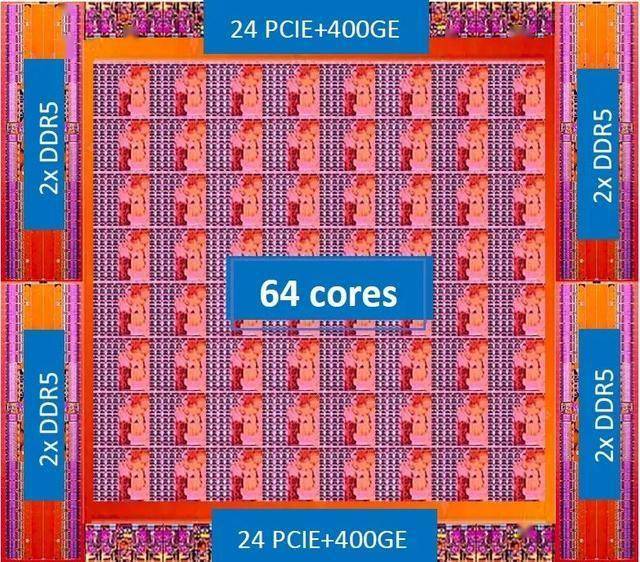
于是,如上图所示,他们开发了第一代芯片。关于这这个设计,Danilak 大胆宣称:“每个核心都比 Xeon 核心或 Epyc 核心更快,比 Arm 核心更小,总体而言,我们的芯片在高性能计算和人工智能方面比 GPU 更快。”
在当时,该芯片的核心如下图所示:
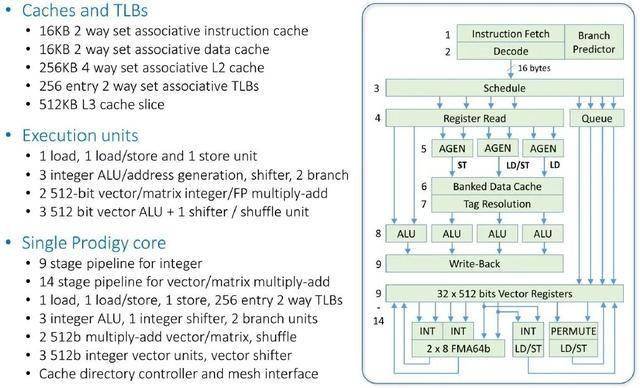
与其他核心设计相比,L1缓存略小,数据缓存和指令缓存均为16KB,但核心上的256KB L2缓存和同样位于核心上的512KB L3缓存(两者共同构成一个覆盖整个芯片的32MB共享L3缓存)则完全正常。如您所见,整数流水线有九级,向量流水线则增加了五级。
以下是 Prodigy 核心如何处理指令获取:
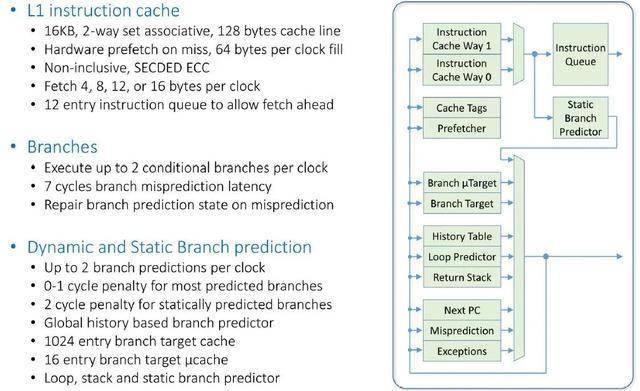
以下是指令执行流程:

这就是 Prodigy 芯片缓存层级结构的实际运作方式:
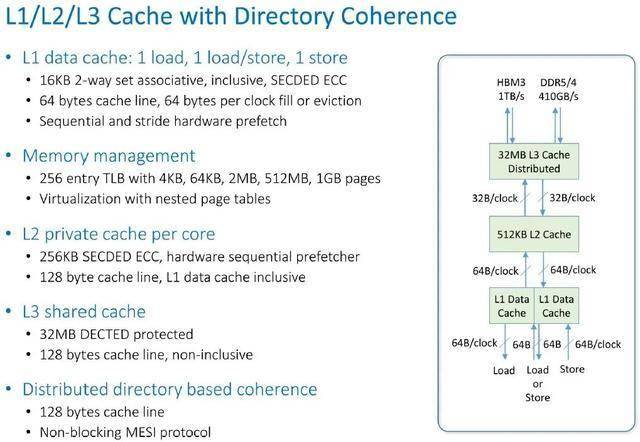
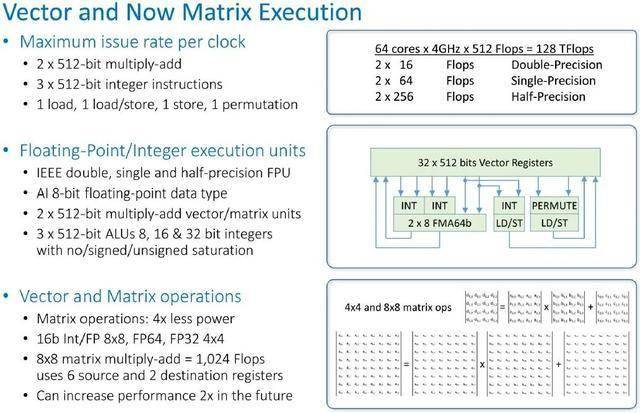
这就是向量和矩阵数学单元的布局和工作原理:
Tachyum原本希望在2019年底推出Prodigy芯片的样品,但由于种种原因推迟了多次。并最终在今天,带来了2nm的版本。
这次真的要发布了吗?
根据最初计划以来,Prodigy通用处理器于2019年完成芯片流片,2020年上市,但此后计划多次调整:从2021年推迟到2022年,再到2023年,最后又推迟到2024年。今年早些时候,Tachyum再次更新了计划,表示将于2025年完成芯片流片,从而推迟了原定于明年第一季度提供的参考服务器样品。
虽然该公司官方仍计划 于2025年开始量产Prodigy处理器,但能否在一年内完成所有必要的里程碑(流片、调试、样品制作、量产启动)仍有待观察。
在去年年底,Tachyum发布了一份长达1600页的指南,旨在优化其Prodigy通用处理器FPGA硬件的性能。我们认为为了帮助大家更好了解这颗芯片的逻辑,可以精简一下这些内容给大家看一下。
据介绍,Prodigy指令集架构(ISA)融合了RISC和CISC两种架构的元素;据Tachyum公司称,该ISA避免了传统CISC处理器中常见的复杂、冗长且效率低下的变长指令。所有指令均标准化为32位或64位,部分指令还集成了内存访问功能以进一步提升性能。
Tachuym 的 Prodigy FPGA 内置性能计数器,可对运行时事件进行实时监控和分析。该公司表示,这些工具能够帮助程序员和工程师识别性能瓶颈并优化代码,从而提高效率,使该处理器成为高要求计算任务的理想之选。
本手册提供了具体的优化技巧,包括管理调度限制、改进内存例程、对齐分支和指令以及缓解寄存器转发难题。此外,它还提供了处理缓存操作、加载/存储对齐和访问特殊寄存器的指导,确保开发人员能够对软件进行微调,从而达到最佳性能。
Tachyum创始人兼首席执行官Radoslav Danilak博士表示:“软件程序员、测试工程师、编译器开发人员以及系统和解决方案工程师将会非常珍惜这次深入了解Prodigy如何为高效处理AI、云计算和高性能计算工作负载提供固有性能优势的机会。Prodigy的集成功能将帮助用户实现业界领先的计算效率,从而更快地获得洞察、更快地开展研究、更快地生成结果。”
对啦,今年十月,Tachyum透露,一家欧洲投资者将在一个月内向Tachyum的账户汇出2.2亿美元的投资款项。此举将助力Tachyum成为人工智能数据中心市场领先的赋能者之一。此外,该C轮投资者还签署了一份价值5亿美元的Prodigy芯片采购订单。Prodigy芯片将使人工智能性能提升一个数量级,并将超大型LLM/AI模型的成本降低约两个数量级。
聪明的读者,你对这颗芯片怎么看?
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






